Sum-Check Protocol spiegato ai newbie
Un algoritmo fondante della crittografia in informatica, con parecchi risvolti pratici

Oggi vorrei presentare un argomento un tantino più teorico del solito, che riguarda una tecnologia che usiamo quasi ogni giorno senza badarci: sto parlando della crittografia, e nello specifico del modello che permette a due attori (ad esempio in rete) di “fidarsi” l’uno dell’altro, e garantire la trasmissione sicura dei dati. Per farlo, è necessario introdurre i sistemi IP (Interactive Proof) e uno dei cardini assoluti della crittografia, noto come Sum Check Protocol.
In un sistema IP (da non confondersi con gli indirizzi IP, che sono tutt’altro) sono consentite due proprietà speciali: la prima è la randomness, la seconda è l’interazione. Se la seconda è quasi ovvia nel suo significato, vale la pena inquadrare meglio la prima: per randomness si intende la casualità del dato, intesa in termini statistici come “non prevedibilità” o non determinismo.
In informatica teorica si chiamano Interactive Proof System (sistemi di dimostrazione interattivi) le macchina astratta in grado di modellare il calcolo come scambio di messaggi. Tale scambio avverrà tra un dimostratore (prover) e un verificatore (verifier). Le due parti interagiscono scambiandosi messaggi più volte fino ad accertare se una stringa sottoposta al sistema appartenga o meno al linguaggio di riferimento. I messaggi vengono inviati tra il verifier e il prover finché il primo non riceverà una risposta al problema e, al tempo stesso, non si sarà "convinto" che è quella corretta.
È bene specificare che le due proprietà di cui sopra sono strettamente funzionali al protocollo: se il verificatore non avesse a disposizione la randomness, non avrebbe modo di testare casualmente ciò che riceve, per cui diventerebbe deterministico, il sistema diventerebbe inutile: tutte le prove sarebbero accettate così come sono. Se possiede la randomness, in altri termini, significa che non sa in anticipo che cosa gli sarà richiesto. Privato della componente interattiva, al contrario, il sistema in sè non sarebbe controllabile, perchè si limiterebbe a scegliere a caso.
Da un lato, quindi, abbiamo il prover, che afferma di sapere o possedere qualcosa: dall’altro troviamo il verifier (verificatore), che invece ha l’incarico di verificare, per l’appunto, che il prover stia dicendo la verità o, se preferite, non stia barando.
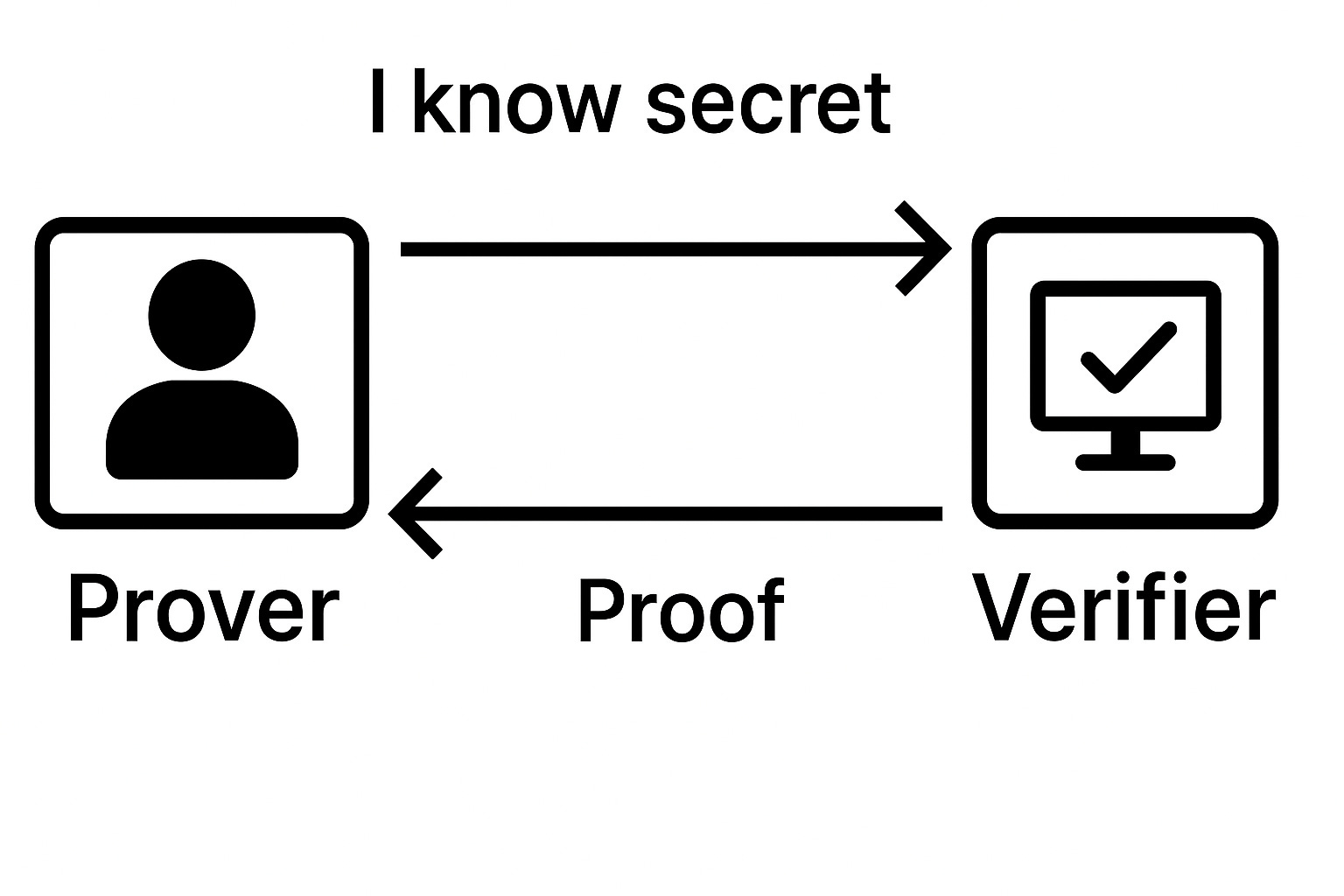
La dinamica dei sistemi Interactive Proof è centrale per qualsiasi sistema crittografico, e qui vale la pena ricordare che per crittografia intendiamo lo studio e l’analisi dei crittogrammi mediante tecniche di cifratura, utilizzati in informatica per garantire comunicazioni sicure, integre e riservate.
E a livello pratico, ancora una volta? Pensiamo ad una PEC in cui vogliamo essere sicuri non solo che le identità comunicati siano chi dicono di essere (un contribuente e l’Agenzia delle Entrate, ad esempio), ma anche che il messaggio sia integro e non sia stato - ad esempio - alterato da terzi (un importo da pagare di 100, 200 o 1000€). Grazie a sistemi su questa falsariga è possibile realizzare quanto richiesto.
I sistemi basati sul modello Interactive Proof sono complessi da un punto di vista teorico ma sono altrettanto interessanti da quello computazionale. Fin dai primi anni Novanta è noto con certezza (è stato dimostrato) che IP coincide con la classe di problemi PSPACE. Senza scendere in ulteriori dettagli, questa classe raccoglie tutti i problemi informatici che possono essere risolti:
1) usando una macchina di Turing deterministica;
2) sfruttando una quantità di memoria (ovvero di space, spazio) polinomiale
Questo si sintetizza dicendo che possiedono complessità computazionale pari a:
il che, tradotto in termini pratici, significa che se n è la dimensione dei dati in ingresso del problema, sarà sempre possibile risolverli in uno spazio polinomiale con esponente k.
Questo garantisce che lo spazio in memoria sia ragionevolmente “contenuto” e non sia, ad esempio, esponenziale o fattoriale, il che renderebbe impraticabile approcciarli - semplifico un po’ per amor di brevità, ma ce ne sarebbero da specificare a riguardo.
La dinamica dei sistemi IP rimane centrale in crittografia, in quanto permette di garantire un tipo di comunicazione sicura, autenticata e integra. Ma non solo: i sistemi IP sono preziosi per i sistemi zero-knowledge, che richiedono per l’autenticazione di conoscere una password senza bisogno di rivelarla esplicitamente. Bitchat Mesh funziona su questo assunto (è ancora in fase test, al momento in cui scrivo), ma si potrebbero fare molti altri esempi.
È un dato di fatto, per inciso, che questo approccio non sia universale e spesso gli sviluppatori rinuncino a implementarlo per paura che il livello di sicurezza elevato renda l’applicazione poco pratica (il che, naturalmente, è una trappola concettuale: se l’app è semplicistica diventa popolare, e i rischi si propagheranno in proporzione).
Il metodo crittografico noto come zero-knowledge proof (prova a conoscenza zero) soddisfa tre proprietà: la prima viene detta completeness (completezza), e assume che se verifier e prover sono onesti, il sistema passerà sempre il test (con probabilità 1). La seconda è detta soundness (solidità, vigore), e assume che se si dovesse presentare un prover truffaldino il verifier non potrà essere raggirato (se non con probabilità molto bassa). La terza proprietà nota come zero-knowledge, infine, assume che nessun dettaglio ulteriore venga utilizzato durante la prova (come un dato personale, ad esempio), se non quelli strettamente definiti dal test.
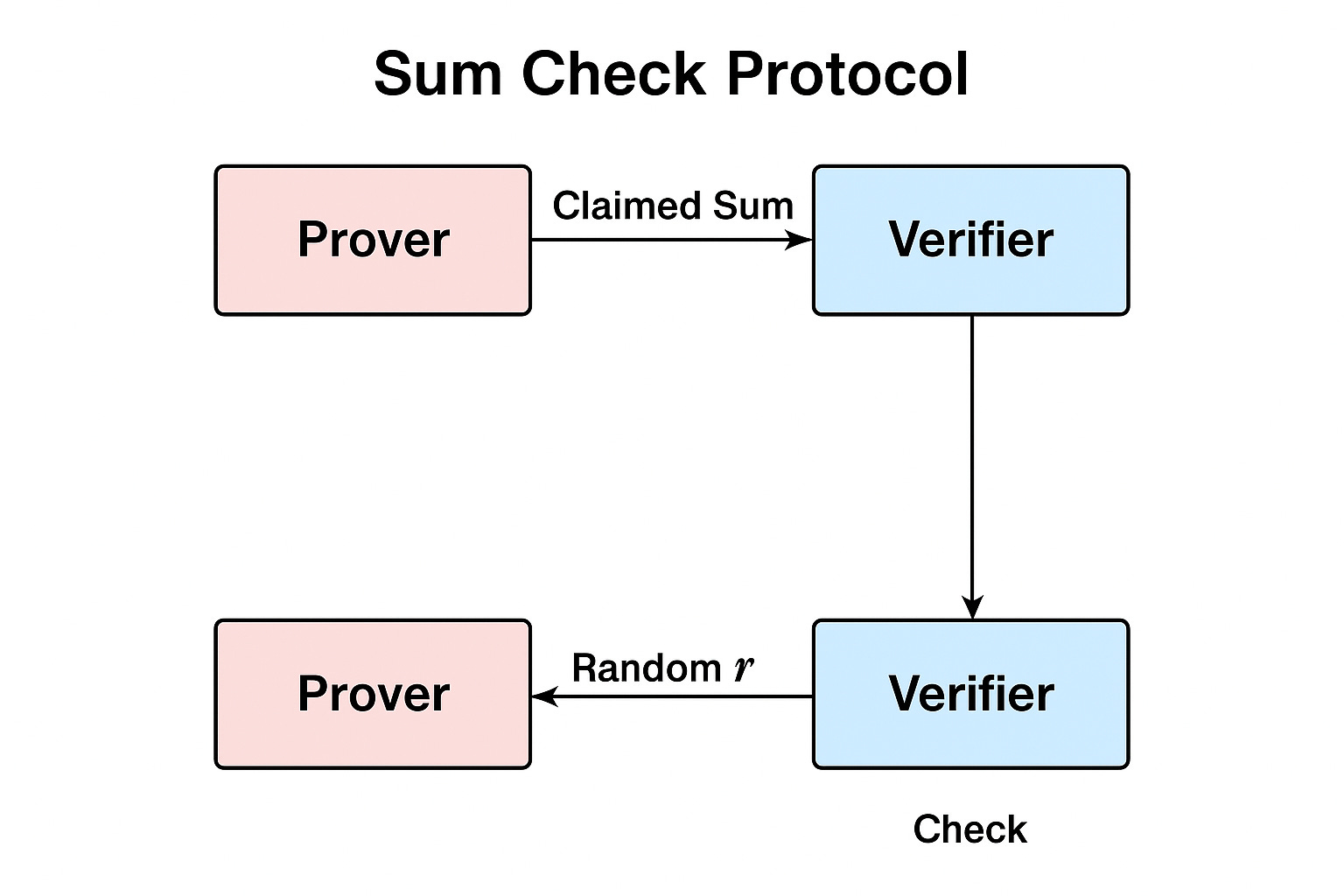
Per effettuare prove certe ci sono numerosi metodi, e quello sicuramente core o alla base di tutti gli altri è noto come Sum-Check Protocol. SCP sfrutta i polinomi di grado n per “comprimere” e verificare velocemente l’informazione richiesta, sulla base di proprietà specifiche dei polinomi stessi. Non sarebbe infatti agevole trattare i dati alfanumerici o binari così come sono, motivo per cui si ricorre ad una loro rappresentazione in termini polinomiali.
Se rappresentiamo i dati e le verifiche della nostra comunicazione verifier-prover come polinomi, avremo due vantaggi:
Caso 1 - se il prover dice la verità, ovvero è davvero chi dice di essere, il polinomio utilizzato da prover coinciderà con quello usato dal verifier (il piccolo dettaglio da mettere a fuoco, qui, è che si confrontano i risultati, non i polinomi in sè, anche perchè sarebbe troppo pesante confrontarli se di grado k molto alto e, al tempo stesso, questi metodi sono noti in letteratura per essere veloci quanto sicuri).
Caso 2 - se il prover sta barando, il polinomio che propone sarà “quasi sicuramente” diverso dall’originale.
Senza scendere in troppi dettagli - che trovate qui, se interessa approfondire - il protocollo ha lo scopo di convincere il verifier che la somma dei termini di un polinomio sia corretta, senza che il prover debba calcolarli uno per uno (il che renderebbe impraticabile il metodo). Per farlo, saranno sfruttate sia randomness che interaction di cui sopra.
Il polinomio è infatti definito su un iper-cubo di dimensione n, i cui parametri o valori possono essere 0 (se il termine non c’è) oppure 1 (se invece compare nell’espressione). Il Sum-Check Protocol ha pertanto lo scopo di trasformare una somma enorme di termini (esponenziale) in una sequenza di mini-verifiche “a campione” (tecnicamente, su polinomi univariati).
In prima istanza il prover propone il dato polinommiale, ma il verifier non lo controlla puntualmente, al momento della ricezione: lo testa in alcuni punti casuali. se la prova fosse falsa o corrotta, verrebbe scoperto - in virtù del lemma di Schwartz–Zippel - con probabilità quasi certa. Anche qui, senza scomodare troppa teoria, proverò a farmi capire con un caso semplificato.
I polinomi vengono sfruttati in questo contesto perchè sono particolarmente facili da maneggiare, anche per un elaboratore elettronico, e sono al tempo stesso “onesti”, per dirla così: se si prova a mentire per scopi malevoli o si sbaglia in buonafede (truffe, comunicazione corrotta, errori di digitazione…), la situazione viene scoperta, per cui il test non passa. Ed è proprio questa solidità che li rende una colonna portante della crittografia in informatica: garantiscono infatti che solo chi è in grado di accedere al sistema possa farlo, facendo uso di una verifica facile da implementare, oltre che molto rapida.
Se poniamo di confrontare due polinomi definiti come segue:
è abbastanza semplice accorgersi che se li testiamo (ovvero mettiamo un valore arbitrario nella variabile x, per dire: x = 1) a parità di assegnamento ci saranno sempre valori diversi (per x=1, P= 1 e Q=2; per x=2 P=4 e Q=5, …).
Se invece i polinomi P e Q sono:
la situazione è leggermente più ambigua: sostituendo il valore x=3, P e Q valgono entrambi 10, mentre i valori sono diversi per tutti gli altri interi. Basta tuttavia testare il polinomio su vari interi (x=1, 2, 4, 5, …) per accorgersi che la prova è comunque valida. Non è difficile definire dei polinomi e, soprattutto, è agevole implementarli in quasi tutti i sistemi di questo tipo, evitando di esporre più dati del dovuto e garantendo una comunicazione sicura.